In my master thesis I compared techniques that learn to parse a chunk of text from continuous integration log files with the help of only a small number of user-provided examples. A part of my work—the dataset used for my study—was published at the dataset track of the Mining Software Repositories Conference 2020. Link
Abstract
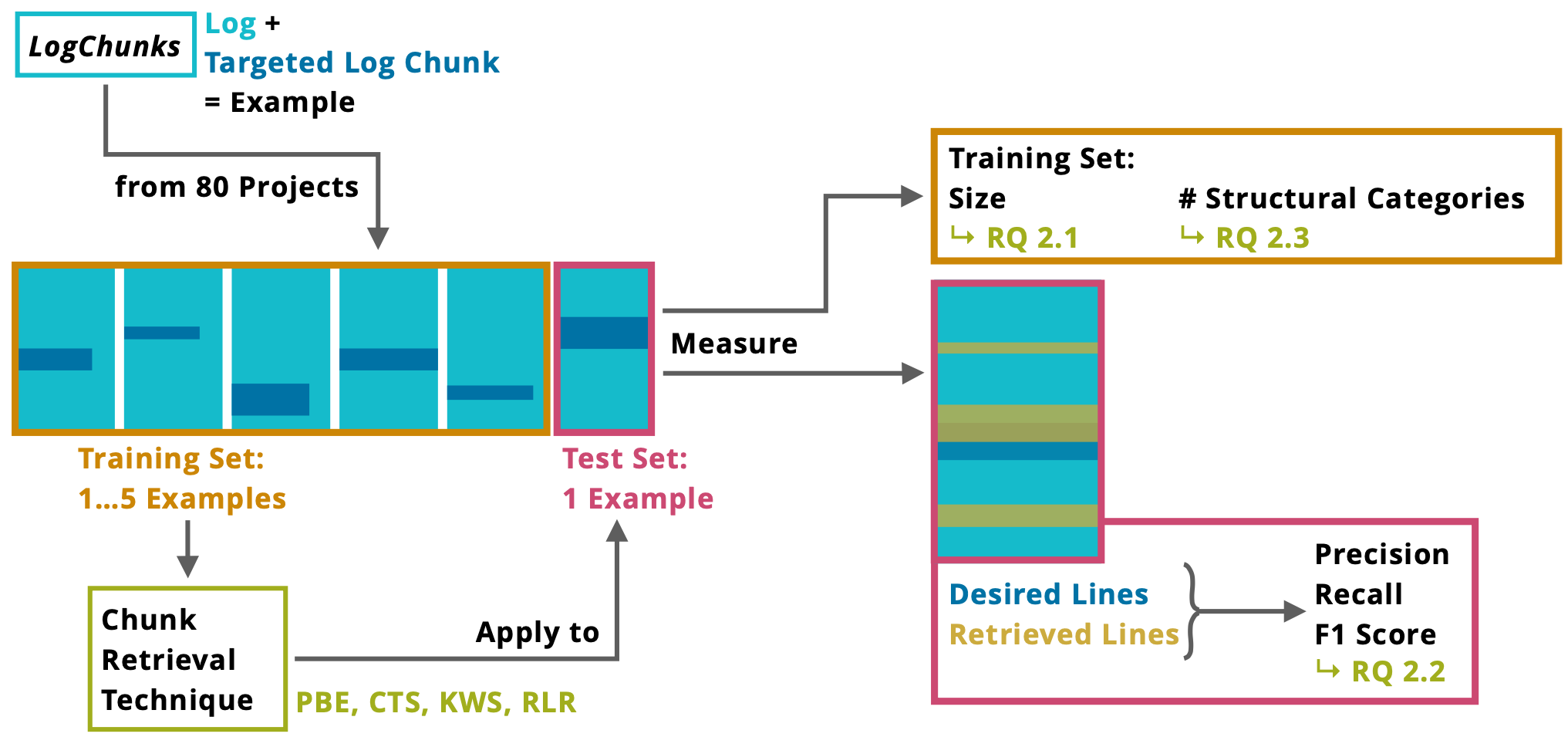
Continuous integration produces detailed logs about the status and results of the various tools involved in the build. These build logs are a valuable data source for developers and researchers to inspect test results, to check the duration of build steps and to understand the cause of a build failure. However, build logs are very verbose, at best semi-structured and their structure differs highly between projects. This makes it hard to process and analyze them. In this thesis, we evaluate and compare three different techniques that aim to retrieve specified log parts (chunks) from a build log, namely program synthesis by example, textual similarity and search keywords. We conduct an empirical study by comparing these techniques on our manually labeled LogChunks data set of 797 Travis CI build logs from a broad range of 80 projects. Our findings show that none of the three techniques in general outperforms the others. We discuss under which circumstances each technique performs best and provide a recommendation on when developers or researchers should use which technique.