This paper is based on Khalid’s Master Thesis, where he investigated how usable tests generated by GitHub Copilot are. We observe that the usability is low, meaning that the developers need to make changes to most generated tests. Less changes are needed when there are already tests existing in the same class and the generated test closely mimics the structure of these existing tests.
Abstract
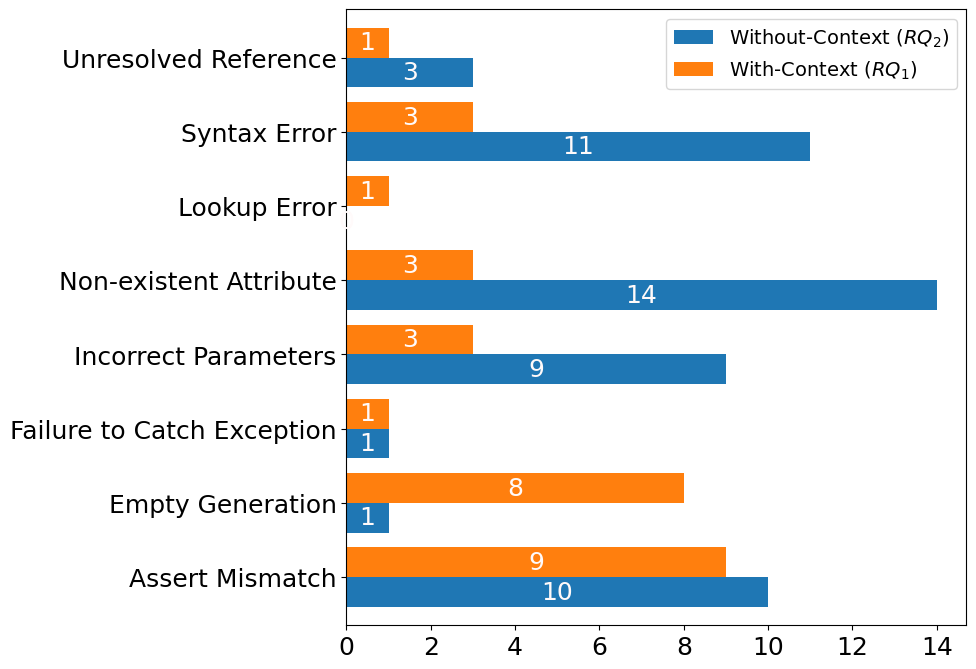
Writing unit tests is a crucial task in software development, but it is also recognized as a time-consuming and tedious task. As such, numerous test generation approaches have been proposed and investigated. However, most of these test generation tools produce tests that are typically difficult to understand. Recently, Large Language Models (LLMs) have shown promising results in generating source code and supporting software engineering tasks. As such, we investigate the usability of tests generated by GitHub Copilot, a proprietary closed-source code generation tool that uses an LLM. We evaluate GitHub Copilot’s test generation abilities both within and without an existing test suite, and we study the impact of different code commenting strategies on test generations. Our investigation evaluates the usability of 290 tests generated by GitHub Copilot for 53 sampled tests from open source projects. Our findings highlight that within an existing test suite, approximately 45.28% of the tests generated by Copilot are passing tests; 54.72% of generated tests are failing, broken, or empty tests. Furthermore, if we generate tests using Copilot without an existing test suite in place, we observe that 92.45% of the tests are failing, broken, or empty tests. Additionally, we study how test method comments influence the usability of test generations.